
Our “four Ps” approach to speech data collection: process, people, platform, and privacy.
Whether it’s to build a speech recognition device or conversational AI platform, developers need high-quality speech data to train and test their machine learning models for an increasingly global customer base.
This challenge is so great that AI developers—even those at the biggest tech companies in the world—outsource their data collection to third-party providers who have spent years developing efficient workflows and technology.
In this article, we’ll discuss how we at Summa Linguae Technologies collect data at scale with a four-pronged approach: in-house operational expertise, a crowdsourced workforce, a data collection and crowd-management platform, and a dedication to privacy and security.
If you like snappy mnemonics, you can call these the four Ps:
- Process
- People
- Platform
- Privacy
Before We Start: Balancing Scalability and Customizability
When companies approach us for speech data collection, they’re typically in one of two situations:
Scenario #1 – You have a mature speech recognition program with clearly defined speech data needs. You may be looking to improve your automatic speech recognition accuracy by 1%.
These companies approach us with specific demographic requirements and quantities. For example, “We need 500 recordings of Japanese speakers saying ‘I want to order a pizza’, distributed evenly across age groups with the following audio quality requirements…”
These companies have a grocery list of needs and it’s about finding a provider that can check all the boxes quickly, efficiently, and at scale.
If your quality requirements aren’t incredibly strict, you’ll be looking for a bulk provider who can offer the data at the cheapest price.
But if you have stricter quality or demographic requirements, you’ll often need to work with a boutique collection agency that can customize your data collection project to your needs (with a collection design that can be repeated at scale).
Scenario #2 – Other companies come to us in proof-of-concept mode. You may not have clear data requirements yet because you’re still qualifying your internal AI models or exploring the speech space for the first time.
For example, you may be looking for spontaneous, unscripted speech commands to see what types of voice commands people want to make for your application.
In this case, you need an innovation partner who can offer clever and cost-effective ways of getting you off the ground. You’ll be leaning on your data collection partner to help you figure out what combination of languages, dialects, and accents you need and in what quantities.
But even if your data needs are smaller today, you should plan to collect data in such a way that can scale in the future, should you want to grow your program. You don’t want to have to switch providers and start over from scratch.
So regardless of whether you’re company #1 or company #2 (or somewhere in between), you should work with a speech data provider who can customize when needed, but also scale up on demand.
Let’s explore the key pillars of what it takes to collect high-quality speech data at scale.
Pillar #1 – Process
Collecting speech data at scale starts with an efficient collection and processing workflow.
Here’s what our end-to-end process looks like at Summa Linguae:
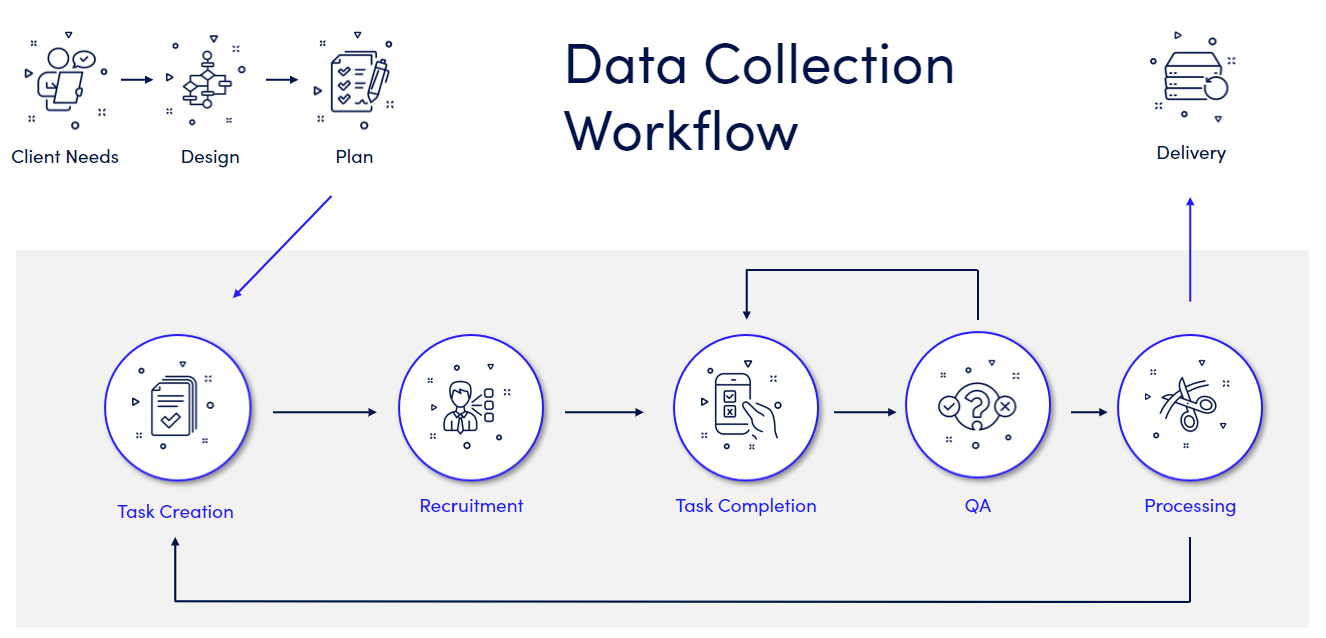
Scoping your needs: The process begins by developing an understanding of your data needs. You may have crystal-clear requirements, or you may need some guidance.
For example, we can help you determine what type of speech recognition data you need, such as:
- Scripted speech
- Scenario-based
- Unscripted or Conversational Speech Data
Design and planning: The next two steps involve solutioning what people, tools, and workflows are required to collect and process the data. Knowing which avenues are most fruitful takes a good deal of experience (e.g. Should you go with crowd collection or voiceover artists?).
Once the project is designed, we can provide an accurate estimate of time and effort.
Task creation: At this stage, we turn the data requirements into a task for a freelancer or crowd participant to perform. This includes breaking large tasks into smaller bits, writing clear instructions, making them available on our crowd platform, and designing the guidelines for our quality assurance process.
Recruitment: With the tasks ready and tested for usability, we begin the recruitment process. We either do this internally with our existing team of resources, or by inviting more users to our crowd platform.
Task completion: This is what takes the bulk of the project time. Because you’re waiting on hundreds or thousands of participants to complete a task, the speech recordings don’t all arrive at once. They trickle in as users take up a task and work on it according to their own schedule.
Quality assurance: Once the audio files have been received, we then check them for quality. If the tasker hasn’t performed to the standards we require, we send them back for rework or reject the submission altogether.
Processing and transcription: Speech collection projects often require transcription of the recorded audio—especially for unscripted speech. This includes labeling to mark sounds and background noises (e.g. laughter or a dog barking). If a lot of speech data transcription is required, we may turn the actual transcription step into a task for the crowd as well.
Delivery: Only after extensive QA do we package and deliver the data to you. For larger projects, we often deliver in monthly batches so you can start using the data ASAP.
But this process is only as effective as the people behind it.
Pillar #2 – People
Large-scale speech data projects depend on gig economy, which is growing at a phenomenal rate.
People are finding that the flexible, temporary freelance opportunities offered by the gig economy suit their lifestyle better than a traditional 9-to-5 office job. In other cases, people are taking on a “side hustle” to supplement their existing income.
• 36% of workers in the US take on freelance work
• 44% of people working in the gig economy use it as their primary source of income
• Total global gig economy spending hit an estimated $4.5 trillion in 2018
• Gig economy is expanding 3 times faster than the total US workforce
This gig economy allows us to collect speech data at high volumes by building our workforce through a variety of online sources:
- Freelance platforms like Upwork
- Targeted ads on social media
- Online freelance communities and groups
- Forums that target the skills and demographics you are looking for
Crowd recruitment does not come without certain challenges, though.
Making speech tasks crowd-ready
One challenge when working with a crowd is making tasks small and manageable enough to be completed at a high success rate. You’d rather collect speech in small segments and offer feedback before moving on to longer segments.
The bigger the task, the more you will see variation in time to completion based on skill level. If the tasks are smaller, your fast workers can complete them faster. The slow workers can be identified earlier and interventions can be applied quicker.
Additionally, bigger tasks require more time for QA. If the quality isn’t up to standard, the more work it takes to redo the task. Smaller tasks allow you to get feedback to the tasker quicker.
The amount speech data you need to train your recognition algorithms will impact the number of participants you need to recruit, plus the number of utterances per participant.
So, for example, you need specifics for following before starting the project:
- Linguistic and demographic variables
- Collection size
- Script
- Audio requirements
- Delivery plan
The longer a task takes, the greater the chance that the member will evaluate the reward for this task versus others. All of this is typical when dealing with freelancers, but by designing the workload to suit them, it’s easier to attract and retain them.
Crowd training and testing
A crowd provides better data if you can train and test them. While many tasks are “unskilled”, some cases may require pre-screening our crowd for skills and matching individuals to specific tasks.
Crowd members can be screened with qualifying project, survey, or test that allows us to vet them appropriately.
For example:
- Voice: A quick recording project that allows users to submit a voice sample allows us to verify their language and specific accent.
- Transcription: A sample test project so taskers can demonstrate they have the required speed, skill, and attention to detail.
Once they pass, they can be invited to the specific project or flagged for inclusion in all future projects that need that skill.
Pillar #3 – Crowd Management Platform
It’s a big task to manage this workflow and the sheer quantity of people involved. That’s why a great technology platform is the backbone of a data collection program.
The more efficient the platform, the better quality the data and the bigger the cost savings.
At Summa Linguae, we built Robson as our remote data collection and crowd management platform.
We went with a hybrid platform approach composed of a mobile app, desktop interface, and backend administration platform.
We’ve concentrated on ensuring the system is solid, robust, and oriented around making the user, QA, and project managers’ experience as simple as possible. By doing that, we ensure that the number of issues escalated to support will get lower and lower over time.
How Robson Works
Robson users are matched to simple tasks based on their profile information, including:
- Gender
- Date of birth
- Home city, region, and country
- Current city, region, and country
- Emigration year
- Mother Tongue
- Education level
The user can view and sign up for all the tasks they’re eligible for. Once assigned to a task, they’ll see instructions and the sentences to record.
After making a recording, the user can play it back, re-record if necessary, or move on to the next utterance.
This data then enters the pipeline mentioned above, where submissions are reviewed for quality, processed, and then securely shipped over to you.
Keys to a Successful Crowd Collection Platform
Here are key elements we prioritized when building our crowd platform to effectively collect, process and deliver large volumes of data.
1. Strong branding and recruitment strategies: People are naturally skeptical about exchanging their data for payment. We therefore had to build trust with potential crowd members that their submissions will be used for good. This requires strong branding and social proof on our website, social media, and app reviews.
For recruitment, Facebook ads are a useful channel to advertise to specific demographics at a relatively low cost. For example, we recently advertised a task for second-language speakers of fluent French:

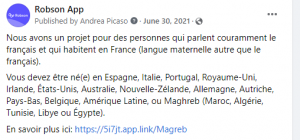
This required targeting people who live in France but were born elsewhere—a tough demographic to find if you’re relying on an organically grown crowd.
2. User-friendly interfaces: Not only does the app have to be functional, it also must provide a smooth user experience to keep users coming back.
We built the Robson mobile app to handle small tasks that can be done anywhere, such as voice recording or quick surveys. The light, frictionless experience of completing small tasks on an app is less cumbersome than having to log into a desktop browser.
However, for bigger tasks that require more screen real estate, such as transcription, a secondary web browser interface is also needed. This allows us to match the right tasks to the right platforms to maximize efficiency and keep costs down.
3. A central administration system: This is the heart of the solution. It links all the parts together to collect and deliver speech data at scale.
It controls the project, interfaces with finance where necessary, sends out the invites to our user base, controls the flow of submissions from the various sources into QA and back out again, and finally it helps manage the payment process for all those users all over the world.
Our QA system is designed to make the process quick and easy so that should rework be needed the feedback is immediate.
This allows us to collect and QA thousands of hours with small core in-house teams.
Pillar #4 — Data Protection and Privacy
Data privacy must be taken extremely seriously. As data stewards for our clients, we’re responsible for the safety and security of this treasure trove. You need to know it’s been protected at every step of the process—from collection, to storage, through delivery.
The following certifications are a must when working in this sphere:
- ISO 9001 – Quality Management
- ISO 17100 – Translation Services-Requirements
- ISO 27001 – The international standard on how to manage information security
Following these protocols ensures we encrypt everything, send everything encrypted, and only make data visible and readable when it needs to be processed.
The one glaring risk remains: What happens if you get PII (personal identifiable information) data inside your collection? In this case, we take an extra step to scrub the data or redact it to ensure what makes its way to you is free of any PII.
We Deliver Speech Data at Scale
Process, people, platform, privacy– these are the four pillars of speech data collection. But these pillars aren’t built overnight.
At Summa Linguae Technologies, we’ve worked for years to develop and refine these processes and platforms.
As a result, our data solutions team is recognized by our clients to be extremely versatile with our outside-of-the-box thinking, but as we’ve developed our crowd and our platform, we’ve gained the ability to offer custom speech data collection at scale.
To learn how we can create a speech collection program for your organization, book a consultation now.


