
It’s fun to see the early results of text-to-image AI capabilities, but it will take some time to achieve picture-perfect success.
Text-to-image artificial intelligence (AI) allows you to generate an image from scratch based on a text description.
Janelle Shane of AI Weirdness recently had fun with the generator, creating corporate logos out of text prompts like “the local Waffle House” and “the Pizza Hut logo”.
She did this using DALL-E 2, a new AI system that creates realistic images and art from a description in natural language.
Like the original, DALL-E, it uses CLIP, a neural network that efficiently learns visual concepts from natural language supervision. OpenAI trained CLIP with a huge collection of internet images and accompanying text.
And as Janelle demonstrates, it generates clear, coherent images. Partly and for now, anyways.
As with any new technology, it’s not without its knots. We’ll discuss what they are and how to untie them below, after digging deeper into what exactly text-to-image AI is to begin with.
What is text-to-image AI?
It’s simple, really. Input any text you can think of, and the AI generates a surprisingly accurate picture that matches your description.
Additionally, the images are generated in a range of styles, from oil paintings to CGI renders and even photographs.
The biggest limit is your imagination.
We’ve already mentioned DALL·E 2, an AI that creates original, realistic images and art from a text description. It also incorporates unique concepts, attributes, and styles.
Additionally, DALL·E 2 makes realistic edits to existing images from a natural language caption. It can add and remove elements while taking shadows, reflections, and textures into account.
Google also announced its own iteration of this technology – Imagen. It’s “a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding.”
Imagen “builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation.”
With both programs, you insert a text prompt, and a corresponding picture is generated. That’s all it takes. You type what you want to see, and the program generates it.
Pretty cool, right? Well, it’s almost too good to be true at this point. By Google’s own admission, there are several ethical challenges facing text-to-image AI.
Let’s explore a couple of the big ones.
Early Issues with Text-to-image AI
Problem #1: Shallow Data Pool
These models need huge amounts of image data and image annotation to turn your text into an image. Specifically, it requires captioned pictures so the AI can learn how to process your request.
It’s like asking someone to draw something in Pictionary. They recall what it looks like from experience and reproduce it on paper. The better the drawing, the easier it is to correctly identify.
The problem is huge quantities of text-to-image AI data are coming from the web.
Many corners of the web, in fact, meaning it doesn’t always come out as appropriately as you’d like. Why not? Their models ingest (and learn to replicate) some abhorrent content you’d expect to find online.
Google’s researchers summarize this problem in a recent paper: “[T]he large scale data requirements of text-to-image models […] have led researchers to rely heavily on large, mostly uncurated, web-scraped dataset […] Dataset audits have revealed these datasets tend to reflect social stereotypes, oppressive viewpoints, and derogatory, or otherwise harmful, associations to marginalized identity groups.”
There’s a need, therefore, for a tighter filtration process to remove questionable content, and better curated and comprehensive data sets.
Problem #2: Outdated Outputs
Text-to-image AI offers remarkably creative renderings and innovative design opportunities. Another issue, though, is the replication of prevailing social biases and stereotypes.
There’s a reason why Imagen and Dall-E-2 haven’t been made available for public use.
For example, Google acknowledges “an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes.”
The output, therefore, is often racist, sexist, or toxic in some way. Check this Twitter thread for some tangible examples.
Early uses of Dall-E-2 have produced problematic results. For example, in an article from The Verge, it’s noted that if you ask DALL-E to generate images of a “flight attendant”, almost all the subjects will be women. Ask for pictures of a “CEO” or even a “lawyer” and you see white men. See more examples here in this Vox article.
This goes back to a lack of complete data. It’s not comprehensive and representative, and bias prevails as a result.
And that’s just scratching the surface. We haven’t even touched on the potential uses of text-to-image AI. The images can easily be used to propagate fake news, hoaxes, or harassment, for example.
So, the red flags are there, and the AI isn’t public in the meantime. But it will be released sooner than later (you can already apply to be a beta user of Dall-E-2), and likely before these issues are resolved.
How To Get the Most Out of Text-to-Image AI
The goal here – and everywhere, frankly – is to reduce bias and increase inclusivity.
How is that achieved? Through comprehensive and properly annotated data.
For text-to-image AI, that means countless pictures with accurate captions for the purpose of machine learning.
If you want the AI to generate more inclusive images, therefore, it must be taught that the output options aren’t limited to stereotypes.
You feed the machine, in other words, and label / tag images like you do with video annotation.
The AI system will be as good as the quality of its input data. “If you can clean your training dataset from conscious and unconscious assumptions on race, gender, or other ideological concepts, you are able to build an AI system that makes unbiased data-driven decisions,” according to AI Multiple.
Now, having said that, they add “it may not be possible to have a completely unbiased human mind so does AI system. After all, humans are creating the biased data while humans and human-made algorithms are checking the data to identify and remove biases.”
But you can at least work to minimize bias, using these steps as outlined by McKinsey:
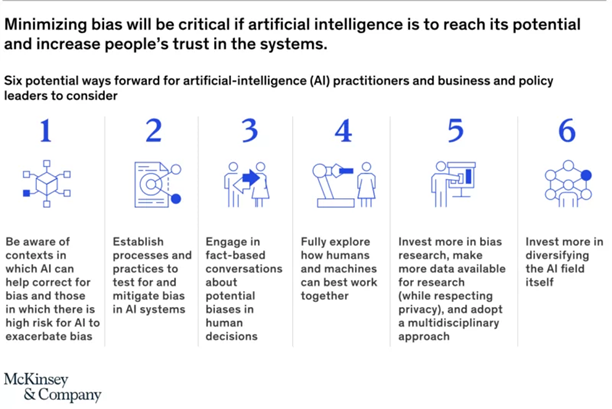
It all starts with comprehensive data collection and labeling. Trained annotators sift through the images and label according to your needs – it’s as simple as that.
If you’re looking to keep costs down and release your AI quickly, rely on an automated solution and limited datasets.
If you want high-quality and comprehensive annotation, find a company that relies on the human eye and quality assurance nets to catch it all.
Feed Your Text-to-Image AI with the Best Text Data Annotation
Annotation gets your AI interacting more accurately with natural language.
Train your algorithm free from biases with our labeling and classification services for text, speech, image, and video data.
We adapt to your unique setup. Enjoy 100% flexibility when it comes to data and file structure.
Contact us today to learn more.


