
The technology has come a long way in a short time. But where is it going and how do we get voice recognition in AI to the next level?
Voice recognition refers to the ability of a machine to receive, interpret, and carry out speech commands. The technology gained prominence with the rise of Artificial Intelligence and voice assistants. Amazon’s Alexa, Apple’s Siri, and the Google Assistant are all commonplace these days.
Generally, these devices make life easier – or that’s the idea, at least.
For instance, maybe you’re a parent and have found yourself in this similar situation. Your Google Nest is set up in your child’s room and connected to a Spotify account. You say “Hey Google, play ocean white noise” to queue some nature sounds to help them sleep. Maybe you didn’t speak clearly enough, or maybe the AI wasn’t been trained to hear your unique voice. Instead, the device starts playing ‘Nights’ by Frank Ocean. It’s a small difference, but it will definitely impact bedtime.
Smart speakers and intelligent virtual assistants are only the beginning. Expect voice recognition in AI to be even more of a thing in the coming years.
As more devices make use of voice recognition, the more precise the voice commands and the desired response must be. If you’re at an ATM or trying to get your coffee order just right, there’s less room for error. And since voice recognition is only as good as what it’s taught, your AI will require a ton of data to reach new heights.
Let’s take a closer look at where voice recognition in AI is headed in the next few years, and how we’re getting there.
The Future of Voice Recognition in AI
The global voice recognition market is expected to increase by 16.8% between 2021 and 2026. What does that look like in terms of dollars? According to stockapps, the market size in 2021 was $10.7 billion, and forecasts show it could grow to $27.16 billion.
From Voice Recognition Assistants to Appliances
“Speech and voice recognition technology is increasingly becoming popular, and we can only expect this trend to keep growing,” said Edith Reads from stockapps. “In the coming years, we expect an increase in the use of smart appliances, going beyond the phones and other devices that we are used to today. This, together with the increased use of artificial intelligence will be the primary factors for the market’s growth.”
With Amazon, Apple and Google dominating the virtual assistant space, developers are coming up with innovative ways to stay competitive and ahead of the game. Companies like Nuance Technologies, for example, are even looking to implement voice recognition across different devices and appliances. This trend may well be adopted by more companies, providing more opportunities for the market’s growth.
Voice recognition technology can be installed in just about any smart machine, including mixers, coffee makers, and refrigerators.
Smarter Voice Recognition Technology
Even as the voice recognition market expands, it’s important to keep advancing its current and common capabilities.
In the phones, laptops, mobile devices, smart speakers, and TVs where its prevalent now, not all languages are supported, not to mention dialects and accents.
Remember, the early iterations of widely used voice assistants only supported a specific and clear version of US English to begin and grew from there. To expand globally, the major voice players have since expanded to their language support to the world’s most popular languages and dialects.
That doesn’t come without growing pains, though. Despite their ongoing efforts to expand their language capabilities, the major voice assistants have received criticism for race, gender, and age biases, for example.
It’s a major problem to solve. In Canada alone, there eight English dialects, two French dialects, and the unique Michif language. On top of that, there are linguistic variation based on gender, education level, economic standing, and plenty of other demographic factors. That doesn’t even include non-native speakers with unique accents, or developments in language over time (e.g. new words or slang).
To create voice technology that understands everyone, voice recognition algorithms must be trained with speech data from people of as many backgrounds as possible.
Taking Voice Recognition to the Next Level
There are two key principles at the core of Rosetta Stone’s philosophy of language learning: 1) The way we learn language as children — immersion in that language — is the best way to learn a new language at any age, and 2) Interactive technology is a powerful tool for replicating and activating that process.
Those same principles apply to improving voice recognition in AI. For the device or application to understand and speak your language, it first must learn it. And that occurs by way of speech data collection and natural language processing.
Why We Need the Data
Let’s go back to the Rosetta Stone comparison. Let’s say you’re planning a trip to Japan, and you want to communicate with the local population as effectively as possible. You want them to understand you and provide the best possible responses to your queries. Maybe you need help with the subway system, or want to order food, for example.
So, what do you do? You sign up for this learning method and learn some Japanese.
It’s the same idea for voice recognition in AI. You need training data for all the target languages you hope to reach with your product to teach it how to interact.
If your voice recognition device is being developed in North America but is intended for use in Japan, it needs to be infused with that data to feed a person looking to make a supper order.
Again, the goal is to make voice recognition capabilities as inclusive as possible, and that occurs by capturing as many combinations of the following as possible:
- Gender
- Age
- Languages
- Dialects
- Accents
- Non-native speakers
While it’s possible you know exactly how you would like your voice data to be structured, the majority come to us with an undefined scope, either because their requirements are flexible, or they haven’t considered all the possible variables yet.
As a speech data provider, we highlight all the ways in which your speech dataset can be customized, and help guide you towards the most effective and price-conscious collection option for your solution.
How We Collect Voice Recognition Data
We wrote about how to collect high-quality speech data at scale but we’ll focus here on the process and let you read there about the three other Ps.
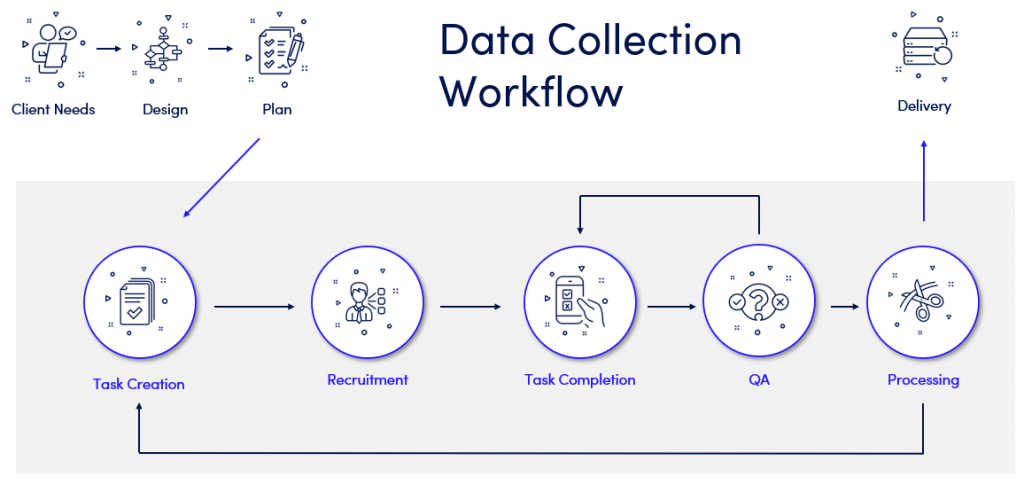
Defining your needs
The process begins by developing an understanding of your data needs. You may have crystal-clear requirements, or you may need some guidance. We can help you determine what type of speech recognition data you need.
Design and planning
Here we map out the people, tools, and workflows required to collect and process your data. Knowing which avenues are most fruitful takes a good deal of experience (e.g. Should you go with crowd collection or voiceover artists?).
Task creation
We turn the data requirements into a task for a freelancer or crowd participant to perform. This includes breaking large tasks into smaller bits, writing clear instructions, making them available on our crowd platform, and designing the guidelines for our quality assurance process.
Recruitment
With the tasks ready and tested for usability, we recruit people to do the recording. We either do this internally with our existing team of resources, or by inviting more users to our crowd platform.
Task completion
This is what takes the bulk of the project time. Because you’re waiting on hundreds or thousands of participants to complete a task, the speech recordings don’t all arrive at once. They trickle in as users take up a task and work on it according to their own schedule.
Quality assurance
Once we receive the audio, we further check them for quality. If the tasker hasn’t performed to the standards we require, we send them back for rework or reject the submission altogether.
Processing and transcription
Voice recognition projects often require human transcription of the recorded audio, especially for unscripted speech. This includes annotation to mark sounds and background noises (e.g. laughter or a dog barking). If a lot of speech data transcription is required, we may turn the actual transcription step into a task for the crowd as well.
Delivery
Only after extensive QA is the data packaged and delivered to you. For larger projects, we often deliver in monthly batches so you can start using the data ASAP.
It’s a big undertaking to manage this workflow and the sheer quantity of people involved. That’s why a great technology platform is the backbone of a data collection program. The more efficient the platform, the better quality the data and the bigger the cost savings.
At Summa Linguae, we built Robson as our remote data collection and crowd management platform. We went with a hybrid platform approach composed of a mobile app, desktop interface, and backend administration platform.
We’ve concentrated on ensuring the system is solid, robust, and oriented around making the user, QA, and project managers’ experience as simple as possible.
Improve Your Voice Recognition Capabilities
Work with a speech data provider who customizes when needed, and scales up on demand.
At Summa Linguae Technologies, we’ve worked for years to develop and refine our process and platform.
As a result, our data solutions team is recognized by our clients to be extremely versatile with our outside-of-the-box thinking, but as we’ve developed our crowd and our platform, we’ve gained the ability to offer custom speech data collection at scale.
To learn how we can create a speech collection program for your organization, book a consultation now.


